Rodina Apple M3 těží z nových funkcí GPU

Aplikace a hry, které využívají Metal API, se zaměřují na specifické funkce GPU Apple Silicon, které jsou ještě lepší s výraznými vylepšeními paralelních procesů v M3 a A17 Pro. Zde je návod, jak to funguje.
Apple zveřejnil vývojářskou přednášku o těchto nových funkcích Apple Silicon GPU, která podrobně popisuje, co se děje pro dosažení lepších výsledků. Video jde do velkých technických detailů, ale poskytuje dostatek vysvětlení v základních pojmech.
Vývojáři vytvářející aplikace s rozhraním Metal API nemusí provádět žádné změny ve svých aplikacích, aby viděli zlepšení výkonu u M3 a A17 Pro. Tyto čipové sady využívají dynamickou mezipaměť, hardwarově akcelerované ray tracing a hardwarově akcelerované mapování sítě, aby byl GPU výkonnější než kdy předtím.
Dynamická paměť jádra shaderu
Dynamické ukládání do mezipaměti je možné díky jádru shaderu nové generace. Při použití nejnovějších jader GPU v A17 Pro a M3 mohou tyto shadery běžet paralelně mnohem efektivněji než dříve, což výrazně zlepšuje výstupní výkon.

Tečkované čáry představují plýtvání pamětí registru
Normálně je GPU schopen alokovat paměť registru pouze na základě procesu s nejvyšší šířkou pásma v rámci prováděné akce po dobu trvání této akce. Pokud tedy jedna část akce vyžaduje podstatně více paměti registru než ostatní, akce využije mnohem více paměti registru pro daný proces.
Dynamické ukládání do mezipaměti umožňuje GPU přidělit přesně správné množství paměti registrů pro každou akci, kterou provádí. Dříve nedostupná paměť registrů se uvolní, což umožňuje paralelní provádění mnoha dalších úloh shaderu.
Flexibilní paměť na čipu
Dříve měla paměť na čipu pevnou alokaci paměti pro registr, skupinu vláken a paměť s vyrovnávací pamětí. To znamenalo, že významné části paměti zůstaly nevyužity, pokud akce využívala více jednoho typu paměti než jiného.
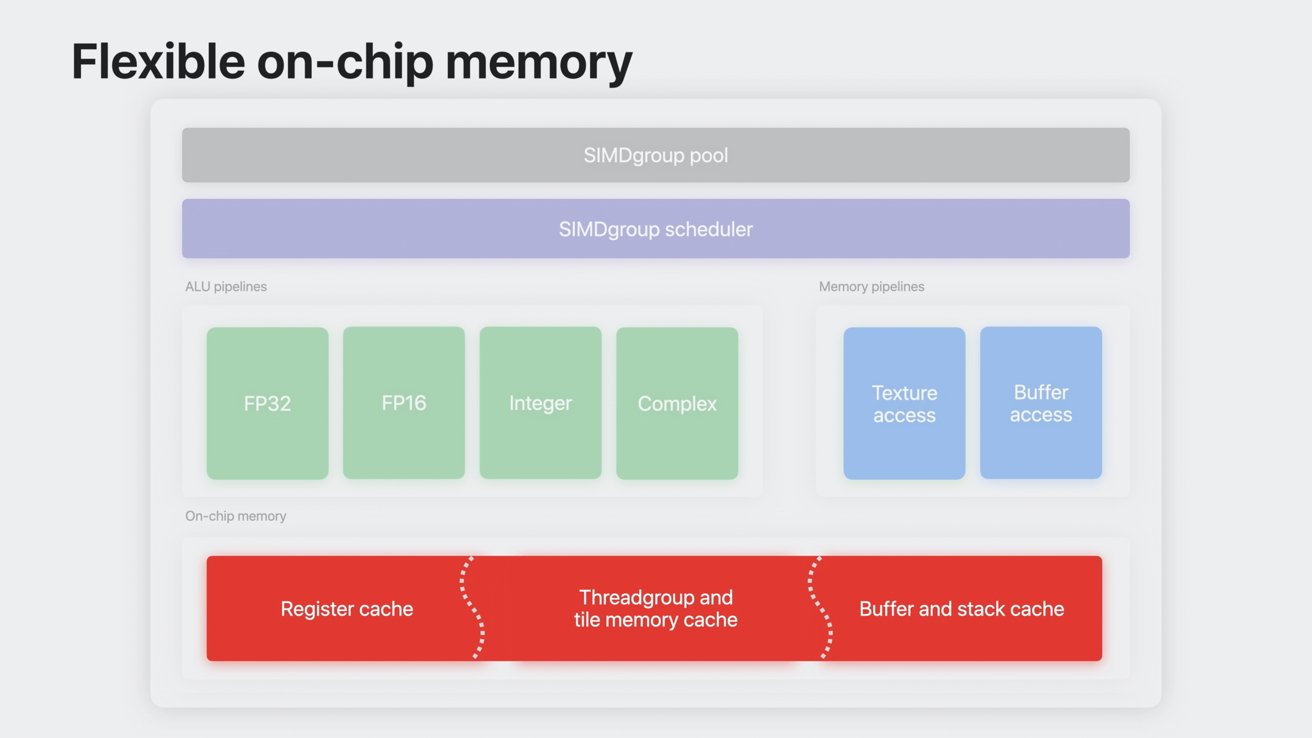
Celá paměť na čipu může být použita jako mezipaměť
Díky flexibilní paměti na čipu je veškerá paměť na čipu mezipaměť, kterou lze využít pro jakýkoli typ paměti. Takže akce, která silně závisí na paměti skupiny vláken, může využít celý rozsah paměti na čipu a dokonce i akce přetečení do hlavní paměti.
Jádro shaderu dynamicky upravuje obsazení paměti na čipu pro maximalizaci výkonu. To znamená, že vývojáři mohou strávit méně času optimalizací obsazenosti.
Vysoce výkonné ALU potrubí Shader core
Apple doporučuje vývojářům provádět ve svých programech matematiku FP16, ale vysoce výkonné ALU spouštějí různé kombinace celých čísel, FP32 a FP16 paralelně. Instrukce jsou prováděny napříč různými akcemi prováděnými paralelně, což znamená, že využití ALU se zlepšuje s vyšší obsazeností.

Zvýšené paralelní operace s vysoce výkonnými ALU potrubími
V zásadě platí, že pokud různé akce obsahují stejné instrukce FP32 nebo FP16, které by byly provedeny v různých okamžicích, mohou se provádění překrývat, aby se zvýšila paralelnost.
Hardwarově akcelerované grafické kanály
Hardwarově akcelerované sledování paprsků tento proces mnohem zrychluje a odstraňuje důležité výpočty průniků z funkce GPU. Protože se o část výpočtů stará hardware, umožňuje paralelní provádění více operací, čímž se urychluje sledování paprsků s hardwarovou komponentou.
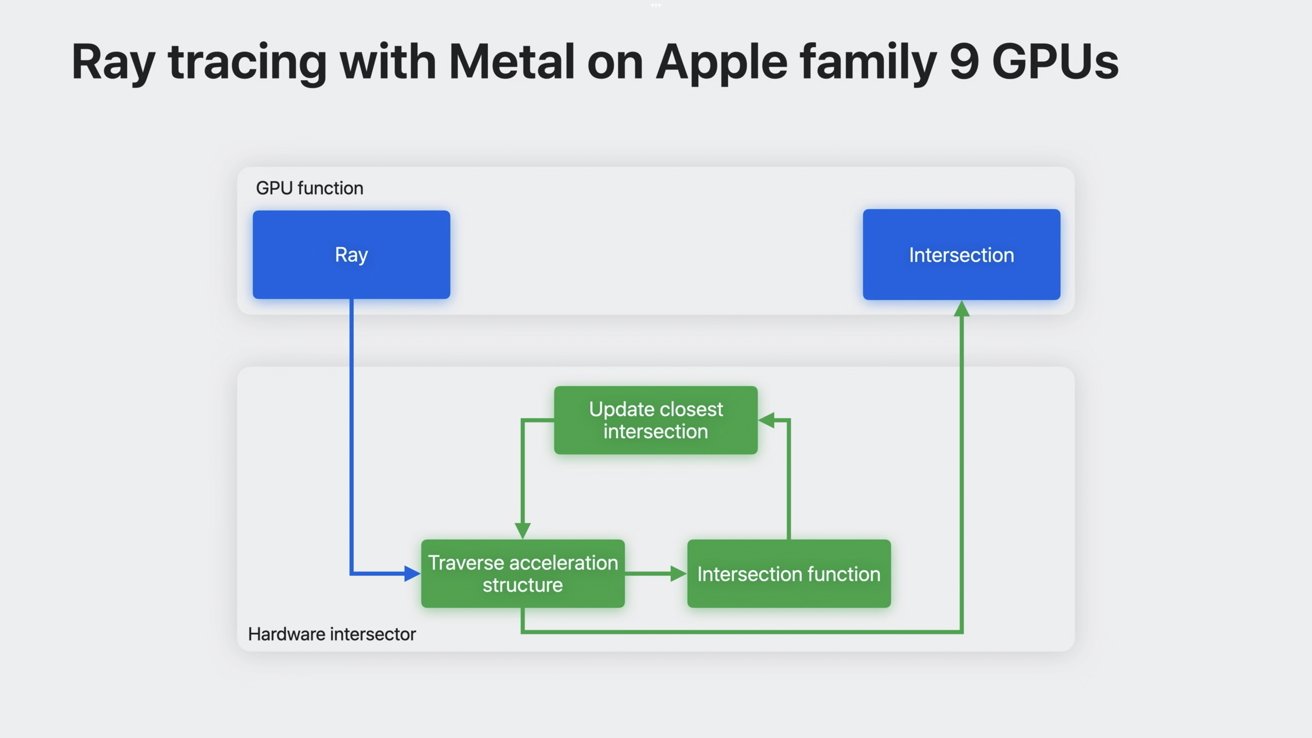
Hardwarová akcelerace přebírá řízení z procesů na čipu
Hardwarově akcelerované síťové stínování využívá podobnou metodu. Vezme střed potrubí geometrických výpočtů a předá jej vyhrazené jednotce, což umožňuje více paralelních operací.
Jde o složité systémy, které nelze rozdělit do několika odstavců. Doporučujeme sledovat video, abyste získali všechny podrobnosti s ohledem na jednu věc – A17 Pro a M3 se zaměřují na výpočetní paralelismus pro urychlení úloh.
Zdroj: appleinsider.com